Database Engines:pgdbe
Tables/Indexes on the SQL Server Professional
The following chapter outlines how the PostgreSQL DatabaseEngine achieves the ability to perform like a navigational data access system even though we are accessing data managed by an SQL DBMS. In the first part of the chapter we will outline how ISAM tables such as DBFDBE or FOXDBE dbf/dbt/fpt are represented on behalf of the SQL Server. In addition, we will learn that the ISAM Emulation requires meta-information stored in system-tables. Then we will walk through each of the ISAM/navigation features and look into how they are represented on behalf of the SQL DBMS.
The chapter closes with an explanation of how the mixing of ISAM/navigational operations and SQL statements, when working with these type of tables, can help to increase your application performance.
It should be noted that there is no need to use SQL commands to manage the data. Developers can stay with the navigational commands and functions. However, specifically in terms of data mining or creating queries, the use of SQL SELECT commands makes a lot of sense and can dramatically reduce the complexity of code while at the same time increase performance.
ISAM dbf tables and indexes are stored in separate files. Data access is typically done using the file-system API on the local disk or remote drive over the network. Either way, the programmer knows the location of the files, their purpose, and how to make use of the files using navigational commands to access data in the most efficient manner. For that purpose, very often indexes are created to increase performance when accessing data or establishing logical orders. Therefore indexes play a special role in the context of ISAM tables - as the name ISAM (index sequential access method) implies.
In contrast, an SQL Database Management System such as the PostgreSQL Server, stores its data at a location not visible to the programmer. In fact, it is the job of the SQL DBMS to hide these details and provide only a view of the data model to the application and/or programmer. This is the first and primary change we need to keep in mind when moving to an SQL DBMS. Because this difference is inherent in the characteristics of an SQL DBMS, and because of the nature of Client/Server technology, there is no way to stay with the existing dbf table and index files.
Therefore, the ability to efficiently move existing applications based on dbf/ntx/cdx/dbt/fpt flat files to the PostgreSQL server largely depends on an automated and easy-to-use method of moving existing data to the PostgreSQL server. For this purpose the Upsize Tool has been developed. The Upsize Tool does almost the entire job of moving existing data from dbf tables and indexes to the PostgreSQL DatabaseServer.
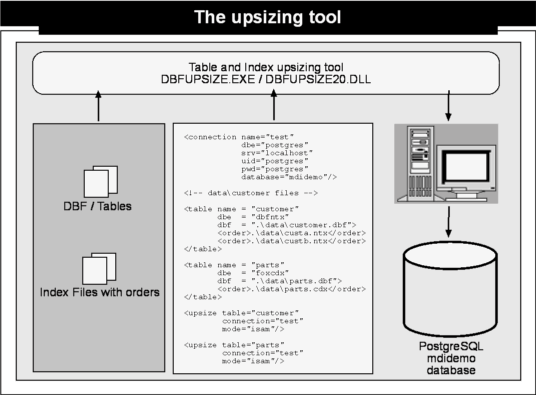
As shown above, the Upsize Tool consists of an executable and a dll. All functionality regarding the upsize process is implemented in the dbfupsize20.dll. An application programming interface (API) is available to automate the upsize process for existing applications, if needed. However the easiest way to handle the upsize process is by using an .upsize file which is in xml format and is shown in the illustration above. The upsize-config sample describes the connection for the upsize process, the source tables, indexes, the related database engine, and the upsize rules. In addition, the upsize config file can include complete database engine setups. The developer can add, rename, or remove columns in target tables, and, if required, can automatically create full-text-search indexes and other extended features. This way it is possible not only to perform a one-to-one upsize, but also to add new features while the upsize process takes place. More details about the Upsize Tool can be found in the Upsize Tool documentation.
In the following example we will use the data files used by the MDIDEMO sample from the Xbase++ standard installation to explain step-by-step how these data files are mapped to the PostgreSQL data model. The files used by the MDIDEMO are the parts.dbf table and the parts.cdx file, used via the FOXCDX DatabaseEngine, and the customer.dbf table with the index files custa.ntx and custb.ntx used via the DBFNTX DatabaseEngine. The following illustration outlines the relationship between the original dbf tables and the resulting data model on the SQL DBMS after having used the Upsize Tool to automatically migrate the tables and indexes to the PostgreSQL DBMS.
Hint: The migration process of the MDIDEMO sample is outlined step-by-step in the Samples And Use Case section. Try it out yourself and use the PGAdmin tool to compare with what the Upsize Tool has done.
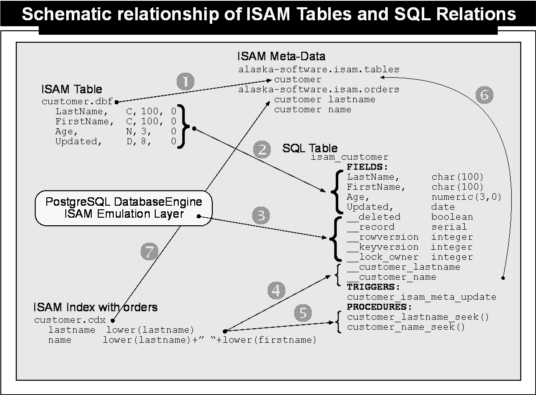
As can be seen in the illustration above, the migration process resulted in the creation of 5 tables on the SQL side: three meta-tables used by the ISAM emulation layer internally to manage ISAM-specific meta data, and the new parts and customer tables.
1.) The customer.dbf table has been added to the ISAM meta-data table's relation. By default the engine manages meta information for the table in this relation. Examples of the related meta information are date-of-creation, date-of-last-update, record-count, update-count, lock-owner, and the UNC name of the originating dbf file.
2.) The structure of the customer.dbf table has been analyzed and re-established as an SQL table or SQL relation using the proper SQL data types.
3.) In addition, the PostgreSQL DatabaseEngine extends the structure or data model of this SQL customer table by adding system-level internal fields/columns which are not visible to the user-level when using this table. Those internal fields are __deleted, used to simulate deleted behavior, __record, used to simulate the record id or record number, __lock_owner, to identify which connection holds a record level lock, and finally __rowversion and __keyversion, used to verify key integrity and detect lost update situations.
4.) Furthermore, new columns have been added which are used to hold the key-values of the former indexes. To understand why indexes need a special column, we first need to look into what indexes are in the ISAM world. In general there, indexes are used to establish logical orders or subsets. In addition, very often indexes are used to create calculated values from one or more fields based on which logical ordering or filtering is in effect. With SQL systems indexes are used quite differently. They are only created to increase performance and in general are not used to create calculated values. In addition, Xbase++ indexes allow the use of user-defined functions, cross-linking of fields in relations, and much more. All of that is not possible with SQL indexes. Therefore the ISAM emulation of the PostgreSQL DatabaseEngine calculates the key-values on the client-side and updates them in the same transaction whenever a record changes. Because index updates are done as part of a transaction, it is no longer possible to have an inconsistency between the record-values and key-values, as they are stored in the same table.
5.) Besides the additional fields for the key-values, the migration of ISAM indexes also results in the creation of stored-procedures for the SQL tables. This is required to provide compatible search capabilities such as seek-first, seek-last, soft-seek, and so on.
6.) The creation of the SQL table has also resulted in the creation of trigger functions which are used to maintain ISAM meta-data on behalf of the SQL server. Those triggers monitor all insert, update, and delete operations to ensure consistency of the meta-data, even though the operations are performed in plain SQL.
7.) Finally there is also a meta-data table for the indexes and its related tags. This table is used to store the tag and bag names, the for and key expressions, and references to the key-columns and key-column-type.
When creating ISAM-like tables and indexes on the PostgreSQL server there are also various constraints applied to the columns. Those constraints are mostly used to ensure consistency of the data model, even though, for example, a table is deleted manually using an SQL DROP TABLE command.
Feedback
If you see anything in the documentation that is not correct, does not match your experience with the particular feature or requires further clarification, please use this form to report a documentation issue.