Database Engines:pgdbe
Data Access Methods Professional
The PostgreSQL DatabaseEngine has a hybrid character which is reflected by its capability to access data on the PostgreSQL server using different data access and data management methods. In the following chapters we will outline each of these methods and describe the scenarios for which they are best suited.
As shown below, the PostgreSQL DatabaseEngine provides two different data access/management methods: ISAM/navigational and SQL/relational. Index-Sequential-Acess-Method (ISAM) is a navigational data access method and therefore is able to support any feature of the well known DBF/NTX/CDX/DBT/FPT DatabaseEngines. All Xbase++ Data Manipulation and Data Definition (DML/DDL) Language functions and commands are supported. The Standard Query Language/SQL access methods allow the use of SQL92 commands to manage and access data. SQL result-sets of queries are reflected in workareas. SQL commands can be sent to the PostgreSQL server using Universal-SQL or Pass-Through-SQL.
Universal-SQL, as the name implies, is a universal SQL syntax. Universal-SQL is available for other DatabaseEngines such as DBF/FPT Engines and for the Advantage Database Server (ADSDBE). This makes it possible to write once but run against any of the given datasources. This is of course not possible with SQL in general because every Database vendor has its own proprietary extensions and syntax. In addition, Universal-SQL is an extension of the standard Xbase++ language. Therefore support from the compiler and tool chain is provided. Besides that, no restrictions apply, so local variables or user-defined-functions can be used inside SQL statements, which of course is not possible in other development languages.
Pass-Through-SQL, on the other hand, is simple to understand as a transparent way to send any SQL command, even the most proprietary, to the PostgreSQL server. As the name implies, SQL commands get passed through to the SQL server without being touched by the Xbase++ runtime. This way, even future commands not known today can be supported.
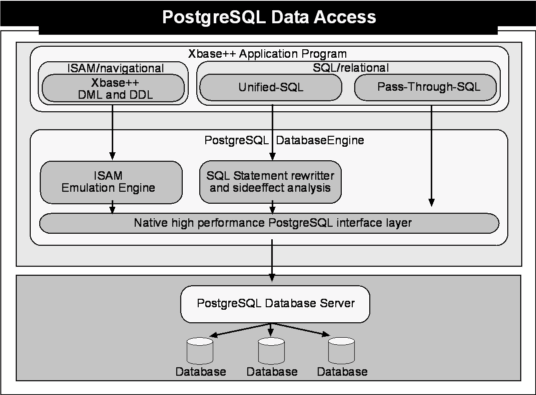
The ISAM Emulation Engine
The ISAM Emulation Engine is responsible for transforming all navigational operations into appropriate SQL statements. The engine manages the order of records based on the hidden field __record or by using the related index column. Index columns not only store the key-value, they also store the tuple (keyvalue,__record) - this way logical orders with same key-values are ordered in physical order as the ISAM/navigational model requires. To avoid repeat SQL select operations against the SQL server, the Emulation Engine has an internal record-cache which uses multi-pages with a maximum lifetime organized in a most recent used list. The intelligent record-cache is required to avoid repeated SQL select operations against the SQL server. Search operations, either by record-number or key-value, are first attempted against the record-cache. If the lifetime of the data is not exceeded, the cache data is used, otherwise the cache-page gets reloaded and the entire snapshot is invalidated.
Besides the basic navigational operations, the Emulation Engine also handles deleted filtering, filters in general, and scope operations. All of these are considered logical extensions to the where clause when composition of the proper select statement is done by the emulation engine.
To increase statement execution performance, the Emulation Engine performs statement preparation (creation of execution plan) and in many cases only needs to change the parameters of a query to present the proper data load to the client.
Table and record level locking are emulated using an inter-process communication between the client stations, thereby avoiding the use of flags in the storage of the table. Only successful table or record locks are maintained by the connection-identifier on a per table or per record case. The result of this approach is that the locking emulation is not only faster than traditional locking using the file-system, it becomes fairly distributed and lock owners can be identified.
Bulk operations such as pack, zap or index rebuilds are done using batched SQL statements. This means the Emulation Engine creates packets of SQL statements which get sent together to the SQL server instead of performing a client/server round trip for each record update. With this approach even a pack operation performs very well.
The SQL Statement rewriter
The purpose of the SQL Statement Rewriter can be described as follows: Take any Universal-SQL statement and rewrite its syntax to conform to the specific requirements of the connected SQL Server. In addition, take any expression and remove all side effects. This means that an expression using a local variable or a user-defined function is rewritten to the proper expression syntax of the SQL server. In addition, the value of the local variable or the result of the execution of the user-defined function is transformed into a literal value conforming to the syntax of the SQL server. The SQL Statement Rewriter is very efficient and the overhead, compared to the SQL statement execution time, is on average less than 1%, which can be considered insignificant.
Feedback
If you see anything in the documentation that is not correct, does not match your experience with the particular feature or requires further clarification, please use this form to report a documentation issue.