Database Engines:pgdbe
Data types Professional
The PostgreSQL Database Management System comes with a rich set of data types. While the Clipper DBF file-format supports only 1 numeric data type and the Visual FoxPro DBF/FPT table supports 4 numeric data types, PostgreSQL comes with 10 different numeric data types. It becomes therefore more important to carefully choose the proper data types in your table designs.
In addition, there are complex data types such as Point or Line which are not reflected by the Xbase++ language and its set of data types. Instead, these rather complex data types are mapped to Objects of specific classes (a class is a user-defined type) which implements the semantics of these special data types.
The following chapters begin with a general introduction into the role and meaning of data types in the context of the Xbase++ language. We then look into the data types of the PostgreSQL DBMS, and finally provide the developer with a guide for which data types should be used in the context of future application development.
Introduction
Xbase++ data types are identified by a single letter equivalent to the return value of the ValType() function. In contrast, data types of the PostgreSQL server are usually identified by symbolic names such as CHARACTER, INTEGER or MONEY. This requires a programmer to know what data types are present in an SQL table and what data type a particular value stored in the table will have when it is assigned to a memory variable in the Xbase++ program. The latter raises another issue: some data types cannot exist in memory but only in tables. An example is variable-length text stored in a memo field of a DBF table. Assume a memo field having the name NOTES:
? Valtype( FIELD->NOTES ) // result: M
cText := FIELD->NOTES // assign contents of field to variable
? Valtype( cText ) // result: C
These three lines of code demonstrate that data type mapping exists already in Xbase++. The data type of the field value is "M" (Memo), and it becomes "C" (Character) when the field value is assigned to a memory variable. Since Xbase++ can be used as a data definition language (DDL) and a data manipulation language (DML), it is important to distinguish between data type mapping for data definition and data manipulation. Data definition means: creation of tables (CREATE FROM, DbCreate()), and data manipulation covers reading/writing of values stored in fields or used in expressions evaluated by the DatabaseEngine or the Server. For example, it makes a difference if two fields are defined having data types "C" and "M", but it makes no difference when the value of either field is manipulated.
The distinction between DML and DDL is of minor importance when data is stored in xBase/dBase/Clipper DBF tables. This is because with these DBF tables, all the data types the dbf table can handle are available for data manipulation. Therefore Xbase programmers are usually not aware of the difference between DDL and DML, since the same programming language is used for both data definition and data manipulation. In addition, the Xbase programming languages hide data type mapping from the programmer, and so does Xbase++/PostgreSQL (the value of a memo field has type "M" and is mapped to type "C" when it is assigned to a memory variable). This hiding of data types is already present for other data types such as the NUMERIC Valtype() with the Visual FoxPro DatabaseEngine, as Visual FoxPro tables support data types such as I (integer), Y (currency) and F(float). All of these specialized numeric data types have been mapped to the Xbase++ DML data type N (numeric), however the single letter type descriptors I,Y and F have been supported for data definition.
With the PostgreSQL server this issue becomes even more visible as there are more than 30 different data types available for table design. The universal DDL and DML types Xbase++ supports are listed below. The data type mappings for the PostgreSQL server are outlined in the following chapter.
DDL-type data types for data definition with Xbase++: A DDL-type is represented by a single letter used to define the data type of a database field. DDL-types are listed in the second column of the DbStruct() array.
Data Definition Language types
| ddl-type | description |
|---|---|
| C | character fixed length |
| M | character data unlimited |
| R | varying character, known maximum length |
| X | binary data, fixed length |
| V | binary data unlimited |
| Z | varying binary data , known maximum length |
| W | Unicode text, fixed length |
| Q | Unicode text unlimited length |
| J | varying Unicode, known maximum length |
| L | logical boolean |
| I | Integer, length can be 2,4,8 to specify integer size |
| F | Approximate numeric, float if length=2 otherwise double |
| N | Exact Numeric or Decimal with precision and scale |
| Y | Currency |
| S | Sequence type, serial or autoincrement |
| D | Date |
| H | Time |
| T | Timestamp |
| E | Interval |
| A | Array |
| B | Block |
| O | Object, class unknown |
DML-type Data types for data manipulation with Xbase++: A DML-type is represented by a single letter equivalent to the return value of the Valtype() function.
Data Manipulation Language types
| dml-type | description |
|---|---|
| U | undefined NIL |
| C | character, can represent binary, character and unicode sub-types |
| N | numeric, can represent Integer, Float and Decimal sub-types |
| L | logical |
| D | date |
| A | array |
| B | block |
| O | object |
| T | timestamp, datetime |
| E | interval |
All of the previous single-letter data type abbreviations which can be used with the Xbase++ CAPI, including their corresponding numeric defines and values, can be found in types.ch.
Data types and mappings
This chapter begins with an overview of the data types supported by the PostgreSQL DBMS. First we outline the data definition (DDL) mappings used to create PostgreSQL Tables. We then look into how the data types are mapped to the Xbase++ language for data access and manipulation. Finally, we outline mappings used by the Xbase++ Upsize Tool.
PostgreSQL available data types
The PostgreSQL server comes with a rich set of built-in data types. We call these types built-in to distinguish them from user-defined-types or user-defined-domains. The current version of the PostgreSQL DatabaseEngine does not support user-defined-types, but domains are supported. However, a discussion about these concepts is beyond the purpose of this chapter. The following table lists all data types supported by the PostgreSQL DatabaseEngine:
Built-in general purpose data types
| Type-Name | Description |
|---|---|
| bigint | signed eight-byte integer |
| bigserial | autoincrementing eight-byte integer |
| bit[ (n) ] | fixed-length bit string |
| bit varying[ (n) ] | variable-length bit string |
| boolean | logical boolean (true/false) |
| box | rectangular box in the plane |
| bytea | binary data (byte array) |
| character varying([n]) | variable-length character string with max length |
| character[ (n) ] | fixed-length character string, padded with blanks |
| circle | circle in the plane |
| date | calendar date (year, month, day) |
| double precision | double precision floating-point number |
| integer | signed four-byte integer |
| interval[ (n) ] | time span |
| line | infinite line in the plane |
| lseg | line segment in the plane |
| money | currency amount |
| numeric | exact numeric of selectable precision |
| path | geometric path in the plane |
| point | geometric point in the plane |
| polygon | closed geometric path in the plane |
| real | single precision floating-point number |
| smallint | signed two-byte integer |
| serial | autoincrementing four-byte integer |
| text | variable-length character string |
| time [ (p) ] [ without time zone ] | time of day |
| time [ (p) ] with time zone | time of day, including time zone |
| timestamp [ (p) ] [ without time zone ] | date and time |
| timestamp [ (p) ] with time zone | date and time, including time zone |
| tsquery | text search query |
| tsvector | text search document |
The sheer amount of available data types for the PostgreSQL DBMS is impressive. However, not all data types supported by the DatabaseEngine should be used when designing your own tables. There are data types such as smallint or real which are there only for historical reasons. Other data types such as inet, cidr and mac are proprietary to the PostgreSQL DBMS and make no sense for the average user. For a discussion on how to choose the proper data type for your own tables, please see the next chapter.
Data Definition mappings
When a table is created by an Xbase++ application, the table structure is defined in an array having four columns. The second column of the array contains letters representing the DDL-types for the table columns. However, not all PostgreSQL built-in data types are supported by the DbCreate() function. The supported PostgreSQL built-in types and their corresponding ddl-type mappings are listed in the following table. Please note that some types require a precision to distinguish them, such as between a 2-byte-signed, 4-byte-signed or 8-byte-signed integer. If no ddl-precision is given, the Xbase++ ddl-type "I" maps to the SQL integer type which is a 4-byte-signed-integer.
DDL mappings
| PostgreSQL-type | Description | ddl-type | ddl-precision |
|---|---|---|---|
| bigint | signed eight-byte integer | I | 8 |
| bigserial | autoincrementing eight-byte integer | S | 8 |
| boolean | logical boolean (true/false) | L | |
| bytea | binary data (byte array) | V | |
| character varying([n]) | variable-length character string with max length | R | |
| character[ (n) ] | fixed-length character string, padded with blanks | N | Length+(Decimals*256) |
| date | calendar date (year, month, day) | D | |
| double precision | double precision floating-point number | F | |
| integer | signed four-byte integer | I | |
| interval[ (n) ] | time span | E | |
| money | currency amount | Y | |
| numeric(p,s) | exact numeric of selectable precision | N | |
| real | single precision floating-point number | F | 4 |
| smallint | signed two-byte integer | I | 2 |
| serial | autoincrementing four-byte integer | S | |
| text | variable-length character string | M | |
| time [ (p) ] | time of day without timezone | H | |
| timestamp [ (p) ] with time zone | date and time, including time zone | T |
Notes:
There is no support for the time with timezone and for timestamps without timezone. This is by design. Even so, the SQL standard requires, and PostgreSQL supports, the time with timezone data type. In reality this type is useless for a simple reason: timezones may shift the date if time wraps after or before midnight. Therefore a time with timezone is not able to reflect the correct time either way.
There is no support for varbinary ('Z') and binary ('X') data types, as is the case with the Visual FoxPro Database Engine. This is right now a limitation of the PostgreSQL server, as it does not support binary and varbinary data types.
The NUMERIC(p,s) data type is mapped to the Xbase++ Numeric ddl-type. The SQL standard defines precision (p) and scale (s) in a way which is different than the xBase Numeric( length, decimals ) definition. The Engine uses the following algorithm to calculate the precision and scale based on given length:
// If decimals are given we need to remove the decimal point
// from the length to get the precision.
IF (decimals > 0)
precision = (length - 1)
scale = decimals
ELSE
precision = length
scale = 0
ENDIF
Data manipulation mappings
In the following table we outline the data manipulation and data access mappings. This is the type a variable has after the value of a field is assigned to it. These mapping are consistent over the different access methods. In other words, DML mappings are identical between the result-sets of a Universal SELECT statement, a pass-through SELECT, and the USE command. The DbStruct() function can be used to determine the DDL mappings for any of these access methods.
Built-in types mapped to Xbase++ ValType() function's return value
| Type Name | DML Type | Comment |
|---|---|---|
| bigint | N | |
| bigserial | N | |
| bit[ (n) ] | C | Bit data type is represented as string of 0 and 1 |
| bit varying[ (n) ] | C | |
| boolean | L | |
| box | O | Object of class GeoBox |
| bytea | C | |
| character varying([n]) | C | transformation from unicode to runtime charset occurs automatically |
| character[ (n) ] | C | transformation from unicode to runtime charset occurs automatically |
| cidr | C | IPv4 or IPv6 host address and optional subnet. 192.168.1.0 or 192.168.1.3/32 |
| circle | O | Object of class GeoCircle |
| date | D | |
| double precision | N | |
| inet | C | IPv4 or IPv6 host address and optional subnet. 192.168.1.0 or 192.168.1.3/32 |
| integer | N | |
| interval[ (n) ] | C | |
| line | O | Object of class GeoLine |
| lseg | O | Object of class GeoLineSegment |
| macaddr | C | Format: xx:xx:xx:xx:xx:xx |
| money | N | |
| numeric | N | |
| path | O | Object of class GeoPath |
| point | O | Object of class GeoPoint |
| polygon | O | Object of class GeoPolygon |
| real | N | |
| smallint | N | |
| serial | N | |
| text | C | transformation from unicode to runtime charset occurs automatically |
| time [ (p) ] [ without time zone ] | C | |
| time [ (p) ] with time zone | C | |
| timestamp [ (p) ] [ without time zone ] | C | Range 4713 BC - 5874897 AD, resolution 1 microsecond |
| timestamp [ (p) ] with time zone | C | |
| tsquery*) | unclear text search query | |
| tsvector*) | unclear text search document | |
| uuid | C | Format: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx, |
| xml | C | xml data transformed to runtime charset |
Upsize Tool mappings
The Xbase++ Upsize Tool uses dedicated mappings when upsizing existing DBF/DBT or DBF/FPT tables to the PostgreSQL server. The following tables give an overview about these fixed mappings with respect to the DBFDBE and FOXDBE Database Engines. In addition, a table with the Visual FoxPro ddl-types is provided for those cases in which a Visual FoxPro data model is migrated over to the PostgreSQL server.
Upsize mappings of DBF/DBT tables
| Dbf ddl-Type | PostgreSQL built-in-type | Comment |
|---|---|---|
| L, Logical | boolean | |
| C, Character | character | converted to UTF-8 |
| D, Date | date | |
| M, Memo | text | converted to UTF-8, no binary data allowed |
| N, Numeric | numeric |
For DBF/FPT tables created with Visual FoxPro or Xbase++ using the FOXDBE DatabaseEngine, the following ddl-type mappings are applied by the Upsize Tool in addition to the previous ones.
Upsize mappings of DBF/FPT tables for Xbase++ users
| Dbf DDL Type | PostgreSQL built-in Type | Comment |
|---|---|---|
| F, Float | double precision | |
| X, Binary | bytea | length is ignored |
| I, Int | integer | default to 4 byte signed integer |
| V, Blob | bytea | |
| T, Timestamp | timestamp with timezone | |
| Y, Currency | money | |
| R, Varchar | character varying(n) | if decimals>0, n = length+(decimals*256) |
| Z, Varbinary | bytea | length is ignored |
| S, Sequence | serial | defaults to 4 byte signed integer serial |
| E, Interval | interval | |
| O, Generic | bytea |
The following table shows the mappings the Upsize Tool uses with respect to the Visual FoxPro ddl-type as defined by Visual FoxPro.
Upsize mappings of DBF/FPT tables for Visual FoxPro users
| ddl-Type | PostgreSQL built-in-type | Comment |
|---|---|---|
| W, Blob | bytea | |
| C, Char, Character | character(n) | if decimals>0, n=length+(decimals*256) |
| Y, Currency | money | |
| D, Date | date | |
| T, DateTime | timestamp with timezone | |
| B, Double | double precision | Precision with FoxPro is only a display hint, therefore ignored |
| G, General | bytea | |
| I, Int, Integer | integer | 4-byte-signed-integer |
| L, Logical | boolean | |
| M, Memo | text | |
| N, Num, Numeric | numeric | |
| F, Float | double precision | Length and decimals are ignored, VFP display only |
| Q, Varbinary | bytea | length is ignored |
| V, Varchar | character varying |
Choosing the proper data type
Selecting the proper data type for a field in a table can sometimes be a difficult task. In general there are two kinds of considerations which drive this decision: the semantics of the field and the technical factors such as performance and storage space. As a rule of thumb, always favor semantic arguments over technical factors. We will discuss this in more detail at the end of this chapter. The first part of this chapter will give the developer a basic guide for choosing between the most common and most confusing data types based on pure semantic considerations.
Choosing the proper Numeric data type
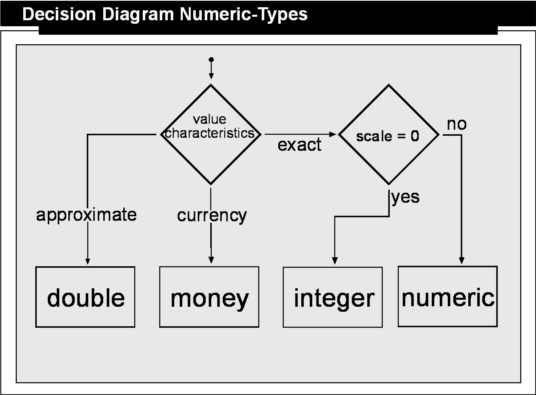
The following decision diagram provides a guide for choosing the proper numeric data type. The first decision which needs to be made is about the characteristics of the value you want to store. If it is the price of a product or the current amount in a bank account, then it is a currency value and the MONEY type needs to be used. As a rule of thumb, when it comes to financial data always use MONEY if it is a currency value, otherwise use NUMERIC.
All other types of numeric values need to be first checked for their requirements with regard to behavior in arithmetic operations. We need to ask if we require exact arithmetic results or do we need a wide range of values. Approximate numeric values such as DOUBLE,FLOAT and REAL are perfect to represent very large or very small numbers, but this comes at the cost of exactness. Approximate numeric data types do not store the exact values specified for some numbers. They store a very close approximation of the value, which is why they are called approximate. In many applications this tiny difference between the specified value and the stored approximation is not visible, but with arithmetic operations the difference becomes noticeable because of the accumulating effect. Avoid using approximate numbers in fields with which you want to do comparisons, specifically the = and <> operators. It is best to use only > and < operators with approximate numbers. If you need to use the equal or unequal operators you need to at least round both numbers before the comparison.
To decide if you need exact or approximate values, think about it as following: if you begin with numbers that are almost correct and do computations with them using other numbers which are almost correct, you can easily end up with a result that is not even close to being correct. Therefore, if you want to do computations with the values stored in a field, use the exact numeric types such as NUMERIC and INTEGER.
If you need an exact numeric type, check first if there is a need for a scale. If so, choose NUMERIC, otherwise use INTEGER for a scale of 0.
Choosing the proper Character data type
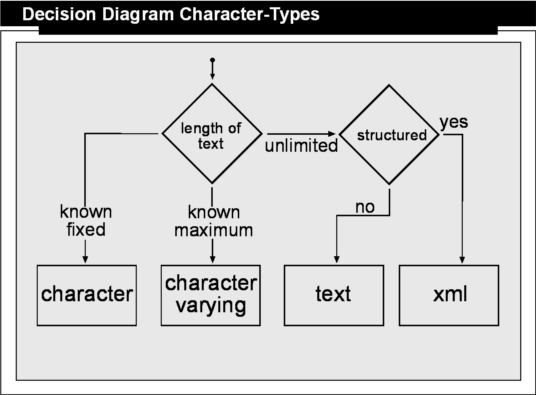
Choosing the proper character type is straightforward. First you need to consider the length of the character data you want to store. If it is not unlimited, the next question is whether the length of the character data is fixed or variable in length but with a fixed maximum length. Lastname and Address, for example, are candidates which have a variable length but for practical reasons are restricted to a maximum size. Therefore, VARYING CHARACTER is the proper type for them. A two-letter country code, a ZIP Code, or even a phone number are entities which are standardized and have fixed lengths, so using the CHARACTER type is the correct choice. Also, as a rule of thumb, use the CHARACTER type for primary-keys or foreign-keys of character data.
In the event your character data is unlimited in length, you need to check if your character data has some structure. A free comment text, for example, has basically no structure, therefore the TEXT data type is the proper choice. However, other textual information may have some underlying structure. If you can identify a structure and don't want to store the information in a separate table, setup an XML file-format and use the XML character type. The PostgreSQL server does validate your XML input data for well-formedness and allows you to perform XPath queries inside the XML data in your SELECT statements. Therefore stored information can be queried by structure and content. Validation against a schema or dtd however needs to be done by your application.
Choosing the proper Temporal data type
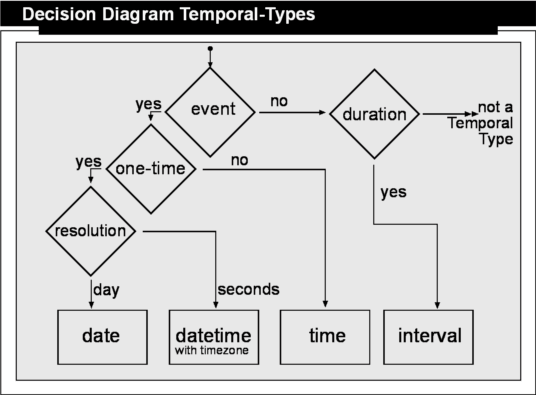
The process to decide which temporal data type should be used, such as DATE, TIME, DATETIME/TIMESTAMP or INTERVAL, is outlined in the decision diagram below. The first question to ask when choosing the proper temporal type is whether you are dealing with an event or a duration.
An event is always a point in time. A point in time can be a day or a specific minute of a day. If you need to store an event, the next question is if the event is an on-time event. Is the event recurring? If it is recurring daily use the TIME type. For any other resolution you need to create your own representation using a NUMERIC or INTEGER data type because the SQL standard does not provide us with a "DAYOFWEEK" or "DAYOFMONTH" data type. Resist using the INTERVAL type for these kinds of recurring events.
If the event is a one-time event, the next question is about the resolution. If the event occurs on a specific day use the DATE type. If the event occurs at a specific time of day use the DATETIME type. Avoid thinking "the more precise the better" and using DATETIME for an invoice date - think about the consequences in your logic. How would you determine all invoices of a specific date? All your queries and comparisons become more complex than necessary. Stay with the resolution you really need to store the point in time.
If the value to be stored is not an event, you need to ask if it is a duration. Durations are expressed using the INTERVAL type. An Interval can be "1h" or "5days 4hours 20seconds", the INTERVAL type supports microsecond, millisecond, second, minute, hour, day, week, month, year, decade, century and millenium as units to specify an interval.
The interval type is only good for a duration, there is no starting point. If you need to describe a period, use a DATETIME field to specify the starting point in time and an INTERVAL field to specify the duration of the period.
Semantic considerations
So far, all decisions regarding the proper data type have been based on semantic considerations. In fact, with data it is all about the meaning of the data. Lets look further into the meaning. A NUMERIC with a scale of 4 and the MONEYdata type behave identically, so from a purely technical point of view there is no difference in behavior, storage requirements or performance. They are technically identical but in terms of semantics they are different. Anyone reading your tables schema almost instantly realizes that a field with the MONEY type is about currency values. Therefore using the MONEY type for your currency values is the only way to go for a simple reason - it documents that the value in this field is a currency-value. Again, it is all about the meaning of your data!
Technical considerations
Technical considerations are often the first thing many technical people think about when choosing a field type. This is natural; technical skills are a core strength of a developer, so there can sometimes be a tendency to make it the most important factor, or even the only factor, in the decision process.
That said, it is important to consider the storage requirements, related performance effects, indexing characteristics, foreign key relationships, and so forth when choosing a column type. But only in the second step and ONLY if you really know what you are doing. As a rule of thumb, increasing performance by upgrading hardware is always cheaper and easier than trying to increase your database performance by tweaking its data types.
In addition, using sub-optimal data types for performance or storage reasons leads generally to more complex code in the business logic, which in turn increases the number of errors in the application. So from a software quality point of view, upgrading hardware is again the cheaper and safer choice.
We will now look into some of the basic assumptions developers tend to make when it comes to tweaking database performance by selecting specific data types.
The SMALLINT pitfall: Developers often think they can increase performance by using SMALLINT instead of the INTEGER data type. This is because the SMALLINT only uses 2 bytes instead of 4 bytes, effectively saving memory and storage space on disk. Unfortunately this is not always true. When it comes to calculations it may more likely become the reverse because the access of a SMALLINT value in memory costs multiple CPU cycles compared to accessing an INTEGER value. Other developers may argue that the amount of data to be read from the hard disk is lower when it comes to a SMALLINT compared to an INTEGER. Unfortunately, the world is no longer that black and white. With current hardware, the performance is mostly restricted by the way main memory is organized and how multiple cores can access that memory. While pure disk i/o was critical in the past, with today's multiple gigabytes of main memory a lot of table data can be efficiently held in memory, ready for processing your queries. The point here is that the effect of your performance tweaking activities largely depends on the underlying hardware, and in some cases may even lead to a performance decrease instead of the anticipated increase.
The VARCHAR versus TEXT trap: Another example of technical considerations driving the decision is the VARCHAR versus TEXT debate. Specifically in the context of the PostgreSQL server, there is no performance difference between these types. Therefore, the developer's line of reasoning often is "I can get unlimited capacity with identical performance, so I should favor TEXT over VARCHAR". A better train of thought would be "this data has a variable length but there is some type of maximum street-name length which makes sense in the real world of address labels". The unlimited length of TEXT is useless in this case, so the "limited" length is the better choice here.
In other words, one mindset thinks lack of control over data size makes the data size very important. The second thinks that lack of control makes the data size irrelevant. A good example in practice of the latter thought process would be a simple data browser or form generator which derives preferred user-interface-components from field-types. Having a VARCHAR for address ensures that XbpSLE() is used, while for a TEXT column an XbpMLE() is used. If all fields such as address, city and comments are of type TEXT, then the form looks very unpleasant for the users.
To sum it up, increasing performance or reducing storage requirements is possible by tweaking data types. But to do it right, a lot of experiments for each specific case need to be done. Of course, all of these tweaks are in almost all cases only valid for specific hardware used with your specific application. Therefore, if ever, tweaking data types should be considered as a last resort and therefore the second step, and never as a part of the initial design process of your database.
Some final comments
Try to avoid using the SMALLINT and REAL data types. Those data types are here for historical reasons and the amount of storage you are theoretically saving is insignificant. In addition, on the downside you are introducing additional complexity into your application's code to deal with these types. REAL numbers behave differently than DOUBLE numbers when it comes to arithmetic results, and a SMALLINT does not match with the INTEGER behavior because of the different ranges.
Unfortunately there are various misconceptions with the temporal data types provided in SQL DBMS systems. Even the SQL standard is extremely ambiguous on that. Let's consider a datetime type. Without a timezone the information stored is always incorrect if used at a different geographical location. The time data type makes, in general, no sense at all as it is more like an interval than a specific point in time. And when it comes to modelling the real world, most systems fail to handle 23:59:60 which is the the so called leap-second time. So what to do? First, when using any of these types we need to make careful decisions. Second, forget about using TIME with TIMEZONE and TIMESTAMP without TIMEZONE. Those types are totally useless in a database. Choosing the proper temporal type becomes easy by asking a few questions about the meaning of the data and how it will be used. Do not use TIMESTAMP without TIMEZONE, there is no benefit in it. Also never use TIME with TIMEZONE as this will always be incorrect.
Use the BOOLEAN type for logical flags if required, but always check to be sure there are really only the two states. If you are not sure, use a single or two letter abbreviation for a status-code which you hold in a separate table. Do not use BIT(1) as a logical value - this will make your queries more complex than required.
Feedback
If you see anything in the documentation that is not correct, does not match your experience with the particular feature or requires further clarification, please use this form to report a documentation issue.