Internet Technologies:hrf
HTML tag manipulation Professional
This chapter describes HRF usage scenarios for manipulating HTML tags.
Retrieving individual HTML tags
A common task in HRF usage is to create HTML pages from template files. Such files contain all HTML tags required for the page design, or the presentation of content, and can be prepared by a Web designer. The content is then inserted dynamically into the template. Assume we want to publish a HTML file displaying the current date (this could be done with JavaScript, but date is a good example for dynamic content). What must be done?
The first thing is to prepare a template file in a way that it can be easily processed by HRF classes, and we use the following template code for our discussion:
<html>
<body>
<p id="TODAY">
$DATE$
</p>
</body>
</html>
The paragraph tag has the ID attribute set, and it embeds the string $DATE$. This is the place where we insert the current date, i.e. $DATE$ will be replaced. This means that the content of the paragraph tag does not matter for the template processing, but it is helpful when the template is designed with a visual HTML editor. In this case, the Web designer gets an idea of what will be displayed in the template file since $DATE$ is visible, while the HTML tags are hidden by the design tool.
The important part for HRF is the ID attribute because it is used to retrieve the HTMLParagraphElement() object when the template file is loaded:
01: // TODAY.PRG
02: #pragma Library( "HrfClass.lib" )
03:
04: PROCEDURE Main
05: LOCAL oDocument := HTMLDocument():loadFile( "$Today.htm" )
06: LOCAL oTag := oDocument:getElementByID( "TODAY" )
07:
08: oTag:childList()[1]:setContent( DtoC( Date() ) )
09:
10: oDocument:saveFile( "Today.htm" )
11: RETURN
The method :getElementByID() is used to retrieve a particular HRF object from the document. It accepts a character string defining the value of the ID attribute. Note that this string is case sensitive, so it is a good idea to use consistently upper or lower case writing for ID values in both, PRG and HTML files.
The textual content of a paragraph tag is stored in a HRF object which is referenced in the first element of the :childList() array (line #8). It is an object of the HRFText() class. This class reflects text embedded between an opening and closing HTML tag. By calling the method :setContent()we replace $DATE$ with today's date. The changed HTML template code is then written into a new file.
The ID attribute is valid in all HTML tags and its value must be unique in a HTML document. Therefore it can be used to retrieve arbitrary HRF objects from the document object via :getElementByID() when the value of the attribute is known.
An alternative to ID is the NAME attribute which is valid in all HTML tags allowing for user input in a Web browser. Such tags must be embedded in a <form>..</form> tag and can be queried using :getElementByName(). Since the NAME attribute is required to obtain input data when a HTML form is submitted, the additional inclusion of the ID attribute would be redundant. However, there is one major difference to the ID attribute: NAME is unique within a form and may not be unique within a HTML document. The method :getElementsByName() is available in the HTMLDocument() class to retrieve all tags having the same value in their NAME attribute.
The following code summarizes the methods available for retrieving individual HRF objects by a symbolic identifier:
// ID= attribute is set
oTag := oDocument:getElementByID( cID )
// NAME= attribute is set
oTag := oDocument:getElementByName( cName )
// Multiple tags have the same NAME= value
aArray := oDocument:getElementsByName( cName )
// Find a tag matching ID= or NAME=
oTag := oHrfObject:getElement( cString )
// Find a tag by tag name
oTag := oHrfObject:childFromTag( cHtmlTag )
Useful links
Filling a multi-selection listbox
There is a variety of HTML tags that are only valid if they are embedded in another particuler tag. The <option> tag is an example for this since it must exist within <select>..</select> and nowhere else, i.e. <option> is always a child tag of <select>. In such a case, the HRF class reflecting the parent tag has methods for manipulating child tags directly.
We will discuss this by filling a multi-selection listbox dynamically in a HTML page and use the template approach as described in the previous section. This is the HTML template code:
<html>
<body>
<form>
<p>Select an option:
<select name="LISTBOX"></select>
</p>
</form>
</body>
</html>
We just fill the days of the week as options into the selection list because this data is easy to create in PRG code. Note that the MULTIPLE attribute is not set in the template, but will be set in the PRG code.
01: // LISTBOX.PRG
02: #pragma Library( "HrfClass.lib" )
03:
04: PROCEDURE Main
05: LOCAL oDocument := HTMLDocument():loadFile( "$Listbox.htm" )
06: LOCAL oSelect := oDocument:getElementByName( "LISTBOX" )
07: LOCAL oOption, n
08:
09: FOR n:=1 TO 7
10: oOption := oSelect:add( CDoW(Date()+n), Dow(Date()+n) )
11: oOption:value := "day" + Ltrim(Str( Dow(Date()+n) ))
12:
13: IF CDoW( Date()+n ) == CDoW( Date() )
14: oOption:selected := .T.
15: ENDIF
16: NEXT
17:
18: oSelect:multiple := .T.
19: oSelect:size := 3
20:
21: oDocument:saveFile( "Listbox.htm" )
22: RETURN
The interesting part of this example program is the FOR..NEXT loop which creates the HTMLOptionElement() objects required to reflect the <option> tags. The objects are not created via the :new() method, but returned by the :add() method in line #10. The HTMLSelectElement() class has this method which creates the child objects and inserts them at the position specified with the second parameter.
An additional value for an option is assigned to an option object in line #11, and today's day is marked as being selected in the list (line #14). The HTML code resulting from template file processing then looks like this:
<html>
<body>
<form>
<p>
Select an option:
<select name="LISTBOX" multiple size="3">
<option value="day1">
Sunday
</option>
<option value="day2">
Monday
</option>
<option value="day3">
Tuesday
</option>
<option value="day4">
Wednesday
</option>
<option value="day5" selected>
Thursday
</option>
<option value="day6">
Friday
</option>
<option value="day7">
Saturday
</option>
</select>
</p>
</form>
</body>
</html>
Compared to the template, the output contains quite a lot more HTML code, of which the data contribute the smallest part. Most of the additional code comes from indentation and the <option> tag. This is something you should be aware of when you create complex HTML pages and publish them on the Web. Indentation is good to check the HTML output for correctness, but it also blows up a HTML file in size which slows down the transfer of the file when it is published.
To keep the file size as small as possible, you can remove all indentation and line breaks by saving the HTML file in this way:
oDocument:saveFile( "Listbox.htm", 0, "" )
The result is a stream of HTML code without superfluous indentation and line-end markers.
Useful links
HTMLSelectElement() class reference
HTMLOptionElement() class reference
HTMLTableElement() class reference
Creating a DBF report in HTML format
One of the biggest advantages of HTML is the fact that this tag language describes the presentation of a document, or how data is to be displayed. There are a variety of tools available which accept HTML formatted files and display their data according to the HTML tags embedding the textual content. The two common HTML viewers are NetScape and Microsoft's Internet Explorer, and at least one of them exists on almost any desktop computer. This leads to an obvious question: Why should you not take advantage of the capabilities of HTML viewers? For example, whenever you need to create a report from your databases that needs to be previewed and printed, you could use the capabilities of an HTML viewer to format your documents.
The HRF is a connection to HTML. HRF is implemented in Xbase++, and Xbase++ gives you database access. This means: HRF can be used as the connector beween data stored in databases and HTML files. The only question is: How to transfer data from a database file into a HTML file? The answer to this question is subject of the following discussion.
The example we have choosen requires very little code and demonstrates the most important aspects: We are going to extract a list of phone numbers from a customer database and list them in a HTML file ordered by customer name. This leads to a tabular DBF report having three columns: Lastname, Firstname and Phone number.
The HTML template
According to the discussions in previous sections, we start with the design of the HTML template file that defines how our report will be presented. The easiest way to accomplish this is a visual HTML editor that displays a HTML file WYSIWYG (what you see is what you get). The display of the HTML template file used in this discussion is shown in the following image and the HTML code of the template comes next.

Template file
01: <html>
02: <style type="text/css">
03: <!--
04: tr {font-family:Arial,Helvetica; font-size:10px;}
05: th {font-family:Arial,Helvetica; font-size:14px;
06: font-weight:bold; color:#FFFFFF;}
07: //-->
08: </style>
09: <body>
10: <table width="350" border="0" cellspacing="0" cellpadding="3">
11: <tr align="left" bgColor="#000000">
12: <th>Lastname</th>
13: <th>Firstname</th>
14: <th>Phone</th>
15: </tr>
16: <tr id="DATA" bgColor="#EFEFEF">
17: <td id="LAST">$LASTNAME$</td>
18: <td id="FIRST">$FIRSTNAME$</td>
19: <td id="PHONE">$PHONE$</td>
20: </tr>
21: </table>
22: </body>
23: </html>
The HTML template uses the <style> tag to define how individual HTML tags are displayed (<tr> in line #4 and <th> in line#5). Using <style> reduces the size of the resulting HTML file, i.e. this approach reduces the download time of the final HTML document.
The HTML code relevant for data transfer is listed in lines #16 to #19: the table row receiving data has the ID attibute set, just as each single cell in the row. The content of the cells in the template is $LASTNAME$, $FIRSTNAME$ and $PHONE$, and this is what is visible in a visual Web design tool.
Template processing
Let us first see how the output of the PRG code processing the template is displayed. The data we have used for the following image comes from the CUSTOMER.DBF file included in the ..\DATA directory of the Xbase++ samples.
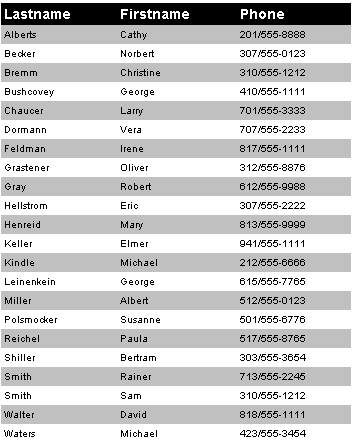
Result of template processing
This image illustrates what the template processor is doing: it uses the HTML code of the template file and fills a table with data coming from a database. The color of each row of data changes, which enhances the readability of the phone-number list.
The PRG code used to produce the phone list is given below. It starts with loading the HTML template file and continues with retrieving the HRF objects required to receive data stored in the CUSTOMER.DBF file:
01: // PHONE.PRG
02: #pragma Library( "HrfClass.lib" )
03:
04: PROCEDURE Main
05: LOCAL oDocument := HTMLDocument():loadFile( "$Phone.htm" )
06: LOCAL oRow := oDocument:getElementByID( "DATA" )
07: LOCAL oTable := oRow:setParent()
08: LOCAL cColor1 := "#EFEFEF"
09: LOCAL cColor2 := "#CDCDCD"
10: LOCAL nCount := 0
11:
12: USE Customer
13: SET INDEX TO CustName // -> Upper( LASTNAME + FIRSTNAME )
14:
15: oRow:destroy()
16:
17: DO WHILE ! Eof()
18: oRow:getElement( "LAST" ):setContent( FIELD->LASTNAME )
19: oRow:getElement( "FIRST" ):setContent( FIELD->FIRSTNAME )
20: oRow:getElement( "PHONE" ):setContent( FIELD->PHONE )
21:
22: oRow:bgColor := IIf( ++nCount % 2 == 0, cColor1, cColor2 )
23: oRow:setParent( oTable )
24:
25: oRow := oRow:clone()
26: SKIP
27: ENDDO
28:
29: oDocument:saveFile( "Phone.htm", 0, "" )
30: RETURN
Line #5
We can recommend from our HRF experience to have a naming convention for the HTML template file and the HTML output file resulting from the template. Our naming convention is: the template file starts with the "$" sign and the corresponding output file has the same name without the "$" sign ( "$Phone.htm" versus "Phone.htm" )
Line #6
The HRF object having the value "DATA" set for its ID attribute is the one which displays $LASTNAME$, $FIRSTNAME$ and $PHONE$ in the template. This object reflects a table row (<tr> tag).
Line #7
The parent object of a table row reflects the <table> tag. The table object must be retrieved to specify the parent for new row objects.
Line #8
The variables cColor1 and cColor2 contain HTML compliant strings for the color definition of table rows.
Line #10
The variable nCount is used to define alternating colors for the rows in the resulting HTML table.
Line #15
The :destroy() method removes a HRF object from the child-list array of its parent. This method call makes sure that the table row displaying $LASTNAME$, $FIRSTNAME$ and $PHONE$ in the template file will not be included in the resulting HTML file.
Line #18
The method call :getElement() retrieves HRF objects reflecting <td> tags, or single cells in the table. The content of the cells is replaced with data stored in the database using :setContent()
Line #22
The effect of alternating colors for each table row is achieved using a counter variable, the modulus operator and an IIf() call. One of two colors is assigned to :bgColor which changes the BGCOLOR attribute of the <tr> tags in the resulting HTML file.
Line #23
Each row object (<tr> tag) must have as parent the table object (<table> tag).
Line #25
The :clone() method duplicates a HRF object. This is an efficient way to create an object having the same attributes and child tags as an existing HRF object.
Line #29
The HTML file is stored without indentation and line-end markers. This leads to a minimum file size.
Conclusions
We have discussed an efficient way to export data from a DBF file into a HTML file. The key is the template file which defines the layout for data presentation. This layout can be canged without affecting the template processing program as long as the ID attributes remain intact. The table row receiving data serves as a kind of sub-template within the HTML file since it is duplicated, or cloned, for each record in the database and only data is replaced in the cloned row object.
Feedback
If you see anything in the documentation that is not correct, does not match your experience with the particular feature or requires further clarification, please use this form to report a documentation issue.