Database Engines:pgdbe
Upsizing existing applications Professional
The PostgreSQL DatabaseEngine allows upsizing existing dbf/dbf/fpt tables and ntx/cdx index-based applications to make use of the PostgreSQL database management system. Very few code changes are required. Upsizing works for both single-user and multi-user databases, even if user-defined functions are used in index expressions. This unique capability makes transforming your existing file-based ISAM application to a full SQL client/server application a snap.
An important warning
The file-based index-sequential access method (ISAM) allows for much higher transaction rates (minimum of 10, up to 100 times) compared to an SQL client/server architecture. The transaction rate directly translates to record inserts or updates. On the other hand, using SQL queries generally is much faster than ISAM query processing, where all data needs to be transferred to the client. This is by its nature, and is not related in any way to Xbase++ or the PostgreSQL DatabaseEngine. Therefore, the benefits and drawbacks should be considered carefully before moving to SQL client/server.
An application can benefit from upsizing to the PostgreSQL server in various ways. The following are generally the most important benefits:
- Higher reliability due to client/server architecture
- Better query and data access performance, specifically in multi-user scenarios involving three or more client stations *)
- Easy SQL integration and the possibility of applying further performance optimizations
Specifically, item #3 is a great plus as the PostgreSQL DatabaseEngine not only provides an ISAM emulation but also transparently supports Universal SQL so that developers can change freely between the different access methods (ISAM and SQL).
Process overview
The first step for upsizing an existing application is to plan the procedure. As outlined in the illustration below, the upsize process can be broken down into four different major tasks.
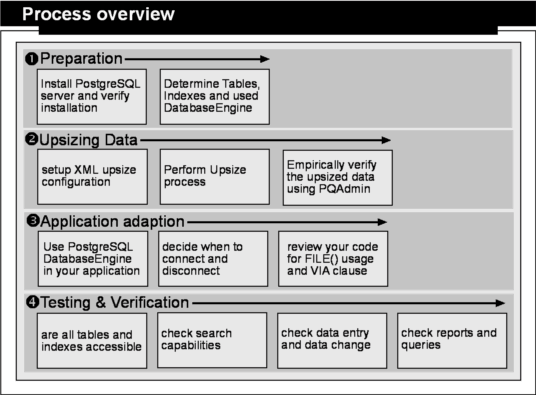
1) Preparation
The process of upsizing an existing dbf/ntx/cdx application requires having a PostgreSQL server installed and configured correctly. For testing, it is recommended to install the PostgreSQL server on the local development machine. The server itself consumes very few resources and does not impede system performance. The server only requires 10-12 MB of RAM and uses almost no CPU time if no client is connected. Even if client applications send SQL commands to the server, CPU utilization rarely goes any higher than 25% on modern CPUs with 2 or more cores.
The second requirement is to determine which data is to be upsized. Depending on the applicaton's specific characteristics, it sometimes makes no sense to upsize all tables. For example, tables which are used only as a temporary intermediate storage -
Old tables no longer used?!?
Changes not done until now, such as increasing a field size.
2) Upsizing data
The entire process of upsizing an existing dbf/ntx/cdx data model to the PostgreSQL server can be fully automated by using the Upsize Tool. The Upsize Tool not only translates the data model and transfers the data, it also warns about issues in the existing data model and helps by altering the data during the upsize.
To control the upsize process, an upsize configuraton file (.upsize) must be created first. The configuration file describes the tables and indexes which need to be upsized. In addition, information about the changes to be applied to the data model is contained in the .upsize file. For example, the upsize process can rename existing columns or change their type. Furthermore, columns can be added to or removed from a table.
Hint: While it may look very attractive to apply changes to the data model while upsizing, it is important to understand that data model (schema) changes always have implications for existing code such as the business logic. Therefore, adding schema changes may actually make the upsize process more complex.
3) Application adaption
After upsizing the data, the existing application code must be adapted. It is recommended to carefully walk through each of the questions given below and take appropriate actions as needed.
When to connect and disconnect? Connecting to a remote server is a relatively expensive operation in terms of time and resources. Therefore, client/server applications typically establish a connection to the server at application startup, and disconnect at application shutdown or when the user logs off. In addition, reacting to power state events to detect system hibernation or sleep is recommended. In fact, the application should perform a disconnect/connect cycle in these cases.
What about multi-threaded applications? It is important to understand that transaction results such as commit and rollback are connection-wide states. It is therefore strongly recommended to create one connection per thread inside a multi-threaded application. Otherwise, threads may interfere with each other on the connection level.
Is the File() function being used? The File() function is often used to verify if a table or an index exists. This is because conditions such as the non-existence of a table or an index need to be handled by the application in a file-based scenario. While table existence can be verified using the Table() function when using the PostgreSQL server, testing for indexes no longer makes any sense. In a client/server application it should be considered a guarantee that the required tables exist. Hint: The same problem may occur with other file primitives such as FErase(). If FErase() is used to erase a table on disk, the corresponding code no longer works when using PostgreSQL. Consider using the SQL command DROP TABLE instead.
Is the VIA clause being used? All occurrances of USE, CREATE FROM, COPY TO, and APPEND FROM commands should be checked for the presence of the VIA clause. Similarly, code using the the dbUseArea() and dbCreateFrom() functions must be verified regarding use of the <cDBE> parameter. After upsizing the data model, the PGDBE needs to be used instead of the DatabaseEngine that was used previously.
4) Testing and Verification
The upsized data needs to be verified. The same is true for the upsized application. A great opportunity for verifying application behavior and query results is created by upsizing an application without adding any kind of new feature or functionality. Even changing the data model, such as by adding columns or changing field widths, should be avoided in the first step.
By having a description of the upsize process in the .upsize file, and by using #ifdefs when adapting the source code, it can easily be ensured that the "legacy" dbf/ntx/cdx-based and the new PostgreSQL-based Xbase++ application can be executed side-by-side. Because they are based on the same data and application code, the basic functionality of the queries and reports can be formally verified in an easy way.
The Upsize Tool - dbfupsize.exe
The Upsize Tool (dbfupsize.exe) is a front-end to the dbfupsize runtime dll (dbfupsize.dll) which implements the entire upsize process. There is also a programmatic interface to the dbfupsize runtime which allows developers to integrate the upsize process into existing applications. However, he easiest way to utilize the dbfupsize runtime is via the Upsize Tool.
By default, the Upsize Tool (dbfupsize.exe) is installed in the Tools menu of the Xbase++ Workbench. In addition, the tool is associated with the configuration files (.upsize). The Upsize Tool can therefore be started very easily for any upsize configuration file which is part of an Xbase++ project file (.xpj). To do this, the file simply needs to be selected in the Project Manager of the Xbase++ Workbench, and the Upsize Tool can then be activated via the context menu.
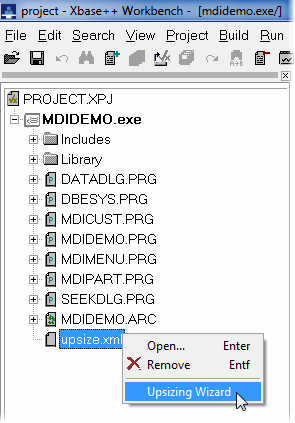
Activating the upsizing in project manager
An alternative way of starting the Upsize Tool is via the command line. Dbfupsize.exe supports the parameters listed below.
DBFUPSIZE [/option] [upsize-configuration-file]
The following options are available:
/?
Display usage screen.
/mo
Data model only. Using this switch, only the data model is upsized and the deferred actions are executed. No data is transferred.
/s
Syntax check only. The Upsize Tool verifies the proper syntax of the upsize definition. In addition, the tool tries to open the source tables and performs a formal validation of the data model to be upsized. No connection is established with the target server.
/st
Single threaded data transfer. By default data is transferred multithreaded via more than one connection to the target server. Using this switch forces the Upsize Tool to run in single threaded mode.
/we
Treat warnings as errors. Any warning which occurs while performing the upsize is treated as an error and a rollback is initiated.
The .upsize configuration file
The Upsize Tool is controlled by the upsize configuration file (.upsize). This is an xml file describing the upsize process. The Upsize Tool first examines the upsize configuration for syntax and semantic correctness before actually commencing the upsize process. In the event upsizing fails, an error is written into the log and the upsize operation is rolled back.
Any .upsize file contains at least the following four elements. The required DatabaseEngines are specified under the <database_engines> element, together with instructions on how to build and load the DBEs. This is followed by the connection which is to be the target of the upsize process. The connection is defined in the <connection> element. Next comes the definition of the source data which is comprised of an arbitrary number of <table> elements. Finally, an <upsize> element specifies the binding between the source <table> and target <connection>. A sample .upsize file is shown below, describing the upsize of a dbfntx-based customer table into the database justonetable hosted by the PostgreSQL server running on the local computer.
01:<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?>
02:
03:<config>
04:
05:<database_engines>
06: <dbebuild name="DBFNTX">
07: <storage name="DBFDBE"/>
08: <order name="NTXDBE"/>
09: </dbebuild>
10: <dbeload name="pgdbe"/>
11:</database_engines>
12:
13: <connection name = "target"
14: dbe = "pgdbe"
15: srv = "localhost"
16: uid = "postgres"
17: pwd = "postgres"
18: database = "justonetable"/>
19:
20: <table name = "customers"
21: dbe = "dbfntx"
22: dbf = ".\\data\\misc\\customers.dbf" />
23:
24:
25: <upsize table="customers" connection="target" mode="isam" />
26:
27:</config>
The lines #1 and #3 are mandatory and identify the file as an xml upsize configuration. Therefore, an empty .upsize file looks as follows.
<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?>
<config>
<!--- your upsize definition goes here -->
</config>
Element: <database_engines>
The <database_engines> element allows <dbebuild> and <dbeload> elements as childs and is used to define the database engines required for the upsize process.
Element: <dbebuild>
The <dbebuild> element requests a DatabaseEngine be built. The name attribute is required and specifies the name of the compound DatabaseEngine. Child elements are <storage> and <order>, each of which has another name attribute giving the name of a dbe to be loaded implicitly.
Element: <dbeload>
The <dbeload> elements describes a DatabaseEngine which is to be loaded explicitly. The name attribute is required and identifies the DatabaseEngine DLL.
Element: <connection>
The <connection> element specifies one or more connections which are uniquely identified by their names. Connections are required in the <upsize> element to define the target of the upsize operation later on. The following table lists all required attributes of a <connection> element.
Required <connection> attributes
| Attribute | Description |
|---|---|
| name | Unique name of the connection |
| dbe | DatabaseEngine used to establish connection with |
| srv | Server to connect to |
| uid | Username |
| pwd | Password |
| database | Target database |
Optional <connection> attributes
| Attribute | Value | Description |
|---|---|---|
| no-smart-order | true | Ensure that upsizing process does not use smart orders |
Element: <table>
The <table> element defines a source table (ISAM) as well as optional orders (ISAM index files). The element allows optional child elements such as <order> and <udfdll>. The following table lists the required attributes of a <table>element.
Required <table> attributes
| Attribute | Description |
|---|---|
| name | Unique name of the table |
| dbe | DatabaseEngine used to establish connection with |
| dbf | Filename and optional path to the ISAM table *) |
*) The path can be relative or absolute. If the path is relative, the location of the .upsize file is used as the drive and directory from which the relative path is normalized. The following shows the <table> element used with and without child elements.
<!-- table element without child elements -->
<table name = "customers"
dbe = "dbfntx"
dbf = ".\\data\\misc\\customers.dbf" />
<!-- table element with child element -->
<table name = "customers"
dbe = "dbfntx"
dbf = ".\\data\\misc\\customers.dbf" >
<order>.\\data\\misc\\customer.ntx</order>
<udfdll>.\\myudflibrary.dll</udfdll>
</table>
Element: <order>
Element: <udfdll>
Index expressions in ISAM tables often contain user-defined functions. Whenever a udf is used, the function needs to be moved into a separate DLL which can then be loaded by the Upsize Tool. The upsized application also needs to contain the user-defined function so the index expression can be evaluated at runtime. However, the implementation of the udf can reside in the executable itself or in a DLL linked to the application. When performing the upsize process programmatically without using the Upsize Tool, the udf dll is not required. This is because in this case the udf is already defined in the upsized application utilizing the upsize runtime.
Element: <upsize>
The <upsize> element binds the source tables defined using the <table> elements to a target <connection> element. It is this element which defines the upsize process in terms of which data is upsized to which database. The following attributes are allowed in the <upsize> element.
Allowed <upsize> attributes
| Attribute | Description |
|---|---|
| table | Name of the table to be upsized. Must be a name of a table element defined previously *) |
| connection | The connection which is used as the target connection to which the table is upsized *) |
| mode | Use "isam" or "sql" as the mode specifier *) |
| as | New name for the upsized SQL table |
|
|
mode='isam': This is the default upsize mode and performs upsizing of an existing table structure and data with full ISAM emulation-support. Specifically, the resulting table maintains record numbers (RecNo()), supports the deleted flag (DELETE/RECALL) and is transparently accessible using both ISAM-navigational and SQL-relational data access and data manipulation commands.
mode='sql': If sql is specified as the upsize mode, the table structure is created on the SQL server and the data is transferred to the server. However, the resulting SQL table does not support the ISAM-navigational access pattern. Only Universal SQL as a relational data access pattern can be used to access the data from within the application.
as: Use the as attribute to specify the SQL table name of an ISAM emulating table upsized from a file-based dbf.
Element: <deferred>
The <deferred> element adds deferred operations to the upsize definition. A deferred operation is executed after the data is transferred to the target connection. In the following example, upsize elements with and without deferred operations are shown.
<!-- upsize customer table to connection one -->
<upsize table="customer" connection="one" mode="isam" />
<!-- upsize customer table to connection two, upsized table name is "customer_001" -->
<upsize table="customer" as="customer_001" connection="two" mode="isam">
<!-- deferred operations, applied after data transfer -->
<deferred>
<rename column="all" name="_all" />
</deferred>
</upsize>
Element: <add>
The <add> element adds a new column to the target SQL table.
Deferred <add> element attributes
| Attribute | Description |
|---|---|
| column | Unique name of the column |
| type | Data type of the column |
| length | Length of a char or varchar column |
| precision | Total count of significant digits. Applies to numerics only |
| scale | Number of digits after the decimal point. Applies to numerics only |
| binding | Comma-separated list of columns for full-text search |
| language | Preferred stop word language for full-text search |
The attributes column, type, length, precision and scale describe a data type supported by the upsizing target specified in the <connection> element. In the context of the PostgreSQL DatabaseEngine, all valid PostgreSQL data types along with their length, precision and scale values are allowed.
By using the Xbase++ proprietary type="fts", a calculated column with full-text search-support is added to the SQL table. In this case, the binding attribute is required. The attribute is a list of existing columns of the table which should be added to the full-text search column. An fts column is a calculated column which is updated automatically each time the columns listed in the binding attribute are manipulated. For this purpose, the upsizing runtime automatically generates update triggers. Like the binding attribute, the language attribute is also required in the case of an fts column. This attribute defines the preferred stop word list used when generating the full-text search index. Stop words are words which are not added to the fts index. In the English language, typical stop words are "this", "is", "he" and so on. Typical German stop words are "er", "sie", "wir", "du" and so on. An ISO two-character language identifier must be used to specify the proper language.
The code below adds a full-text searchable column named "fts_col". The searchable data is automatically created from the values of the firstname, lastname and note columns. Updates of the values of one of these three fields are automatically propagated to the full-text search column. The language used for the full-text search is English, which means that the typical stop words of the English language are automatically removed from the searchable data.
<upsize table="customer" connection="one" mode="isam">
<deferred>
<add column="fts_col" type="fts" binding="firstname,lastname,note" language="en"/>
</deferred>
</upsize>
A full-text search can be performed by using the name of the fts column together with the '@@' full-text search operator and the plainto_tsquery() function. The sample SELECT command below shows a full-text search issued on the fts_col column.
SELECT * FROM customer WHERE fts_col @@ plainto_tsquery('tomato')
Element: <remove>
The <remove> element requires the column attribute and removes the column with the given name from the table. The following code removes the column age and adds the column dayofbirth.
<upsize table="customer" connection="one" mode="isam">
<deferred>
<remove column="age" />
<add column="dayofbirth" type="date" />
</deferred>
</upsize>
Element: <rename>
The <rename> element requires the column and name attributes. The value of the column attribute is the name of the column to be renamed, and the name attribute specifies the new name. The following .upsize definition renames the column company to company_name
<upsize table="customer" connection="one" mode="isam">
<deferred>
<rename column="company" name="company_name" />
</deferred>
</upsize>
Programmatic reference - dbfupsize.dll
The dbfupsize tool is in fact a UI front-end to the dbfupsize runtime dll implementing the upsizing process. The dbfupsize dll can be used from within any Xbase++ application. Redistribution of the dll with your own application is explicitly allowed. This allows integrating the upsize process into existing applications.
DbfUpsize( <cCfgFile> ,<oLogger> )
<cCfgFile>
Fully qualified filename of an .upsize configuration file.
<oLogger>
<oLogger> is an instance of a class implementing the IUpsizeLogger interface. The IUpsizeLogger interface requires the class <oLogger> to implement methods such as :alert(), :output(), :start() and :finish(). The logger object is used to report information about progress, alerts and/or errors back to the caller.
The following code shows the simplest implementation of an upsizing process within an existing application.
#pragma library( "dbfupsize.lib" )
CLASS Logger FROM IUpsizeLogger
EXPORTED:
METHOD finish
METHOD output
METHOD progress
METHOD alert
METHOD stage
METHOD setJobCount
METHOD jobError
METHOD jobFinished
ENDCLASS
//////////////////////////////////////////////////////////////////////
/// <summary>
/// Called when upsizing completes
/// </summary>
/// <returns>self</returns>
//////////////////////////////////////////////////////////////////////
METHOD Logger:finish()
? "### Finished"
RETURN self
//////////////////////////////////////////////////////////////////////
/// <summary>
/// Output a line of text to the log destination
/// </summary>
/// <param name="cTxt">String to output</param>
/// <returns>self</returns>
//////////////////////////////////////////////////////////////////////
METHOD Logger:output(cTxt)
? cTxt
RETURN self
//////////////////////////////////////////////////////////////////////
/// <summary>
/// Progress notification for an upsize job. This can be used to
/// update the UI, for example, by advancing a progress bar.
/// </summary>
/// <param name="nJobId">Numeric id of an upsize job</param>
/// <param name="nPercent">Numeric value between 0 and 100 with the
/// job's completion status</param>
/// <returns>self</returns>
//////////////////////////////////////////////////////////////////////
METHOD Logger:progress( nJobId, nPercent )
UNUSED(nJobId)
UNUSED(nPercent)
RETURN self
//////////////////////////////////////////////////////////////////////
/// <summary>
/// Alert notification. Called when an error occurs during the upsize
/// process.
/// </summary>
/// <param name="cTxt">The message text</param>
/// <returns>self</returns>
//////////////////////////////////////////////////////////////////////
METHOD Logger:alert(cTxt)
MsgBox(cTxt,"Error")
RETURN self
//////////////////////////////////////////////////////////////////////
/// <summary>
/// Stage change notification. Called when the upsizing process
/// advances to a new stage. Examples for state change messages are
/// "Preparing" or "Upsize complete".
/// </summary>
/// <param name="cTxt">The text associated with the stage</param>
/// <returns>self</returns>
//////////////////////////////////////////////////////////////////////
METHOD Logger:stage(cTxt)
? "### "+cTxt
RETURN self
//////////////////////////////////////////////////////////////////////
/// <summary>
/// Notifies about the number of upsize jobs scheduled to run
/// concurrently.
/// </summary>
/// <param name="nJobs">The number of upsize jobs</param>
/// <returns>self</returns>
//////////////////////////////////////////////////////////////////////
METHOD Logger:setJobCount( nJobs )
? "--- Jobs:", Var2Char(nJobs)
RETURN self
//////////////////////////////////////////////////////////////////////
/// <summary>
/// Called when an error occurred while processing a job.
/// </summary>
/// <param name="nJobId">The numeric id of the erroneous job</param>
/// <returns>self</returns>
//////////////////////////////////////////////////////////////////////
METHOD Logger:jobError( nJobId )
MsgBox( "Job ID: " + Var2Char(nJobId), "Error" )
RETURN self
//////////////////////////////////////////////////////////////////////
/// <summary>
/// Called when a job is finished.
/// </summary>
/// <param name="nJobId">The numeric id of the finished job</param>
/// <returns>self</returns>
//////////////////////////////////////////////////////////////////////
METHOD Logger:jobFinished( nJobId )
? "--- Job finished", Var2Char(nJobId)
RETURN self
PROCEDURE Main
LOCAL oLogger
LOCAL lRet
oLogger := Logger():new()
lRet := DbfUpsize("registration.upsize", oLogger )
? IIF(lRet,"Success","Failed")
RETURN
Feedback
If you see anything in the documentation that is not correct, does not match your experience with the particular feature or requires further clarification, please use this form to report a documentation issue.